Nel capitolo precedente abbiamo ottenuto l’elevazione di privilegi sfruttando uno Use-after-Free in Holstein. Alla terza patch, lo sviluppatore del modulo ha finalmente rilasciato Holstein v4, dichiarando che ormai non restano più vulnerabilità e che non ci saranno altri update. In questo capitolo vedremo come exploitare anche questa “versione finale”.
Analisi della patch
Puoi scaricare la versione definitiva v4 da qui. Iniziamo confrontandola con v3.
La prima differenza è nello script di avvio run.sh: il sistema ora viene eseguito in multi-core.
1 | - -smp 1 \ |
Nel modulo vero è proprio, invece, sono state corrette sia la memory leak sia la Use-after-Free.
Il primo cambiamento riguarda open: se qualcuno ha già aperto il driver, la variabile mutex vale 1 è la nuova open fallisce.
1 | int mutex = 0; |
Quindi il driver non può più essere aperto due volte contemporaneamente. Quando il file viene chiuso, mutex torna a 0:
1 | static int module_close(struct inode *inode, struct file *file) |
Allora dov’è la vulnerabilità? Fermati un attimo a pensarci.
Race Condition
L’implementazione può sembrare finalmente corretta, ma in realtà continua a ignorare una caratteristica essenziale del kernel: più processi o thread possono accedere alla stessa risorsa nello stesso momento.
Il sistema operativo esegue il context switch fra thread non a livello di funzioni, ma al livello molto più fine delle singole istruzioni assembly[1]. Questo significa che anche l’esecuzione di module_open può essere interrotta a metà e ripresa in seguito.
In questo capitolo sfrutteremo proprio una Race Condition nata da questa situazione.
Condizione di gara
Vediamo innanzitutto che cosa succede se il context switch avviene in punti diversi. Considera il seguente ordine di esecuzione:
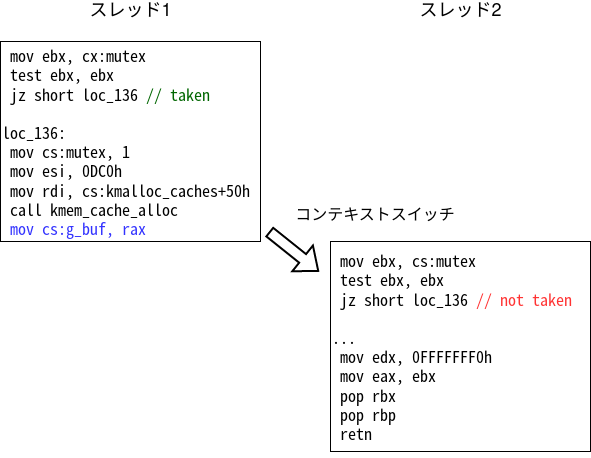
All’inizio mutex vale 0, quindi il thread 1 prende il ramo che alloca g_buf. La scrittura evidenziata in blu salva il puntatore nel campo globale.
Poi avviene un context switch e parte il thread 2. A quel punto mutex vale già 1, quindi il secondo thread prende il ramo di errore e open fallisce con EBUSY.
In questo scenario module_open si comporta esattamente come lo sviluppatore si aspettava.
Ora guarda invece quest’altro ordine di esecuzione:
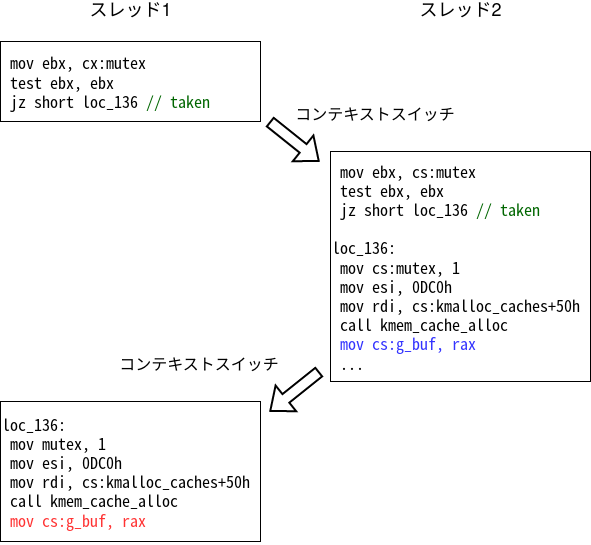
Anche qui il thread 1 entra nel percorso che alloca g_buf, ma questa volta il context switch avviene prima che mutex venga impostato a 1.
Quando parte il thread 2, mutex vale ancora 0, quindi anche lui entra nel ramo che alloca il buffer. Salva il proprio puntatore in g_buf e poi cede di nuovo la CPU.
Quando il controllo torna al thread 1, quest’ultimo completa la propria allocazione e sovrascrive g_buf con il proprio indirizzo. Alla fine entrambe le open hanno avuto successo, ma entrambe le thread finiscono per condividere il buffer allocato dal thread 1.
Questo mostra bene perché il codice kernel deve sempre essere pensato in ottica multithread: se non lo fai, i bug nascono molto facilmente.

Qui il problema nasce dal fatto che letture e scritture di mutex non sono state implementate con operazioni atomiche.
Quando due open riescono contemporaneamente, basta chiamare close su una delle due per liberare g_buf lasciando l’altra ancora in grado di usarlo. Il risultato finale è di nuovo una Use-after-Free, proprio come nel capitolo precedente.
Vincere la gara
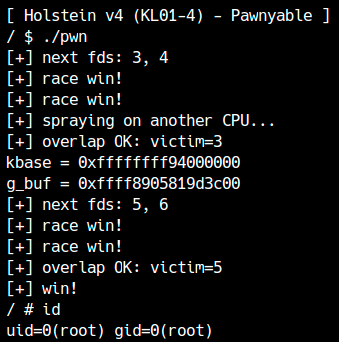
Verifichiamo che questa race sia davvero sfruttabile.
In teoria basterebbe chiamare open da più thread molto rapidamente, ma serve anche un modo per capire quando la race è effettivamente riuscita. I criteri possibili sono tanti; qui l’autore ha scelto di osservare i file descriptor assegnati: se due open hanno entrambe successo, uno dei due fd diventerà necessariamente 4.
Una possibile implementazione, che usa due thread che eseguono la stessa funzione, è la seguente. Ricordati di linkare libpthread con -lpthread.
1 | void* race(void *arg) { |
Con questa logica, la race riesce quasi al 100% e nel giro di pochi millisecondi. Come primitive di exploit, quindi, è più che sufficiente.
Una data race è la situazione in cui due thread accedono contemporaneamente alla stessa locazione di memoria e almeno uno dei due effettua una scrittura. In un linguaggio come C/C++, questo porta a comportamento indefinito. Le data race si risolvono con mutua esclusione o operazioni atomiche.
Una race condition, invece, significa che l'esito del programma dipende dall'ordine di esecuzione dei thread. Non implica di per se comportamento indefinito: spesso significa semplicemente che la logica implementata dal programmatore produce risultati inattesi in presenza di concorrenza.
Nel nostro driver c'è una race condition dovuta a un errore di progettazione, che a sua volta produce anche una data race sul puntatore al buffer.
CPU e Heap Spray
Negli exploit che sfruttano race multithread bisogna tenere presente un altro dettaglio.
Se stiamo eseguendo la gara su più thread, è quindi su più core CPU, il buffer g_buf verrà allocato da uno dei core coinvolti. Qui torna utile ricordare una caratteristica dello SLUB allocator: gli slab usati per l’allocazione sono gestiti per-CPU.
Di conseguenza, se g_buf viene liberato da un thread eseguito su un core diverso da quello del thread principale, il chunk verrà rimesso nella freelist di quel core. Questo vuol dire che un Heap Spray eseguito solo dal thread principale potrebbe non collidere mai con il chunk appena liberato.
In pratica, in una situazione come questa bisogna fare in modo che anche lo spray venga eseguito da più thread / più CPU.
Inoltre, ogni open("/dev/ptmx") consuma un file descriptor, e ogni processo ha un limite. Se servono moltissimi spray, conviene chiudere i descrittori non più necessari appena si individua quello interessante.
1 | void* spray_thread(void *args) { |

Con sched_setaffinity puoi restringere i core usati da un thread, così anche su macchine con molti core puoi riprodurre un comportamento simile a quello di un sistema a 2 core.
Elevazione di privilegi
A questo punto resta solo da procedere come nei capitoli precedenti.
La data race ci permette di costruire una Use-after-Free, poi con l’Heap Spray facciamo atterrare un tty_struct sul chunk liberato e infine completiamo l’escalation.
Il codice di esempio completo si può scaricare da qui.
Gli exploit basati su race condition sono difficili da debuggare. Per questo, all’inizio del lavoro, le domande più importanti sono due:
- la teoria è davvero realizzabile?
- si riesce a costruire una primitive che vinca la race con alta probabilità e in modo stabile?
Se la probabilità di fallimento diventa alta, prova a modificare l'exploit in modo che resti affidabile anche al variare del numero di core.
Alcune CPU riordinano anche l’esecuzione delle istruzioni per motivi di ottimizzazione, ma qui non ci serve entrare in quel livello di dettaglio. ↩︎