In LK03 (Dexter) studieremo una vulnerabilità chiamata Double Fetch. Per prima cosa scarica i file di LK03.
Opzioni di avvio di QEMU
Nel challenge LK03, SMEP, KASLR e KPTI sono attivi, mentre SMAP è disattivato. Ricorda inoltre che la vulnerabilità riguarda una race, quindi il kernel viene eseguito in multi-core[1].
SMAP è stato disabilitato solo per semplificare l’elevazione di privilegi; la vulnerabilità di per se si attiverebbe anche con SMAP attivo.
1 |
|
Analisi del sorgente
Partiamo dal codice sorgente di LK03, che si trova in src/dexter.c.
Il modulo è un semplice device che può memorizzare fino a 0x20 byte e viene controllato tramite ioctl, con due comandi: uno per leggere e uno per scrivere i dati.
1 |
|
Quando il device viene aperto, private_data riceve un buffer da 0x20 byte allocato con kzalloc. Quando viene chiuso, il buffer viene liberato:
1 | static int module_open(struct inode *inode, struct file *filp) { |
Quando arriva una ioctl, il modulo valida la richiesta userland con verify_request, controllando che il puntatore non sia NULL è che la lunghezza non superi 0x20:
1 | int verify_request(void *reqp) { |
Poi CMD_GET e CMD_SET copiano i dati fra userland e private_data:
1 | long copy_data_to_user(struct file *filp, void *reqp) { |
A prima vista sembra che non ci sia spazio per uno heap overflow, proprio per via del controllo in verify_request.
Double Fetch
Double Fetch è il nome dato a un particolare tipo di data race che si verifica in kernel space. Come suggerisce il nome, la race nasce quando il kernel legge due volte lo stesso dato userland.
Se il kernel esegue due fetch distinti dello stesso contenuto userland, fra il primo è il secondo un altro thread potrebbe modificarlo:
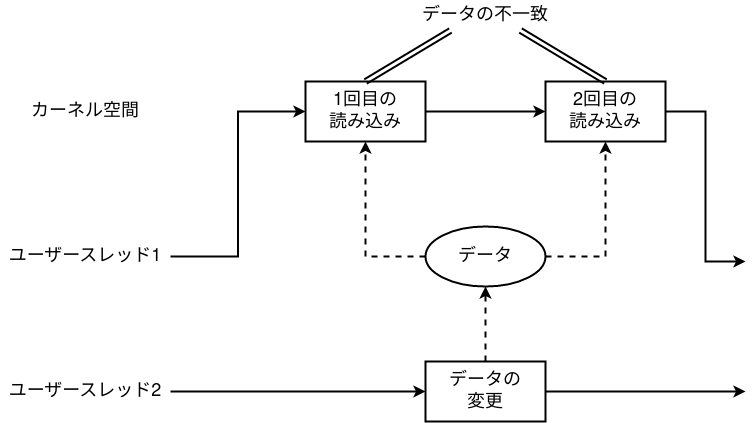
Se questo succede, il primo e il secondo fetch non vedono più lo stesso valore e lo stato interno del kernel diventa incoerente. Questa situazione è ciò che chiamiamo Double Fetch.
La differenza principale rispetto alla race vista in LK01 è che qui il problema non si risolve semplicemente mettendo un mutex nel codice kernel: la sorgente del dato resta in userland e può essere modificata dall’esterno.
Nel nostro driver, la richiesta userland viene letta una prima volta in verify_request è una seconda volta in copy_data_to_user o copy_data_from_user. Se durante quell’intervallo si cambia il campo len, si può superare il controllo iniziale è poi effettuare la copia con una dimensione più grande, causando uno heap overflow.

Quando devi usare più volte dati forniti dallo userland, la cosa giusta è copiarli una volta sola nel kernel e poi lavorare sempre sulla copia kernel.
Innescare la vulnerabilità
Partiamo dall’uso corretto del driver:
1 | int set(char *buf, size_t len) { |
Ora costruiamo una race che alteri la dimensione nel momento giusto. Nell’esempio seguente, il thread principale invoca CMD_GET con la dimensione corretta, mentre un thread secondario modifica req.len in userland.
1 | int fd; |
Se il thread secondario modifica req.len dopo il passaggio in verify_request ma prima della copia effettiva, copy_data_to_user userà una dimensione non più valida e si otterrà una lettura oltre i limiti.
Per CMD_GET basta verificare se siamo riusciti a leggere oltre 0x20 byte. Per CMD_SET, invece, non è altrettanto immediato capire se l’overflow ha davvero avuto successo. Qui l’autore ha scelto una strategia pratica: provare l’overflow per un numero costante di iterazioni è poi verificare il risultato facendo una overread.
1 | void overread(char *buf, size_t len) { |
Nell’ambiente dell’autore, facendo una prova del genere l’overflow ha casualmente corrotto dati sensibili posti subito dietro il buffer e ha prodotto un kernel panic:
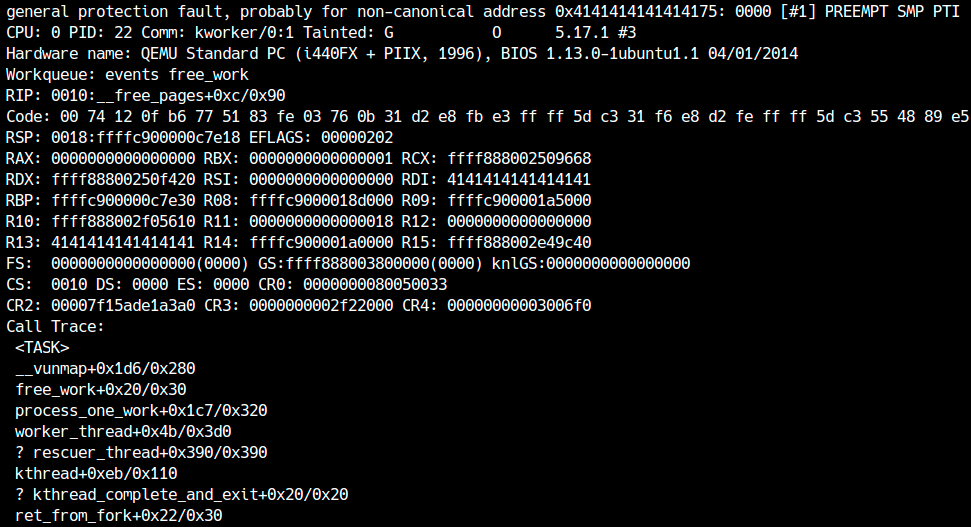
seq_operations
La zona che riusciamo a corrompere appartiene a kmalloc-32, quindi serve un oggetto utile della stessa size class. Un candidato molto comodo e seq_operations:
1 | struct seq_operations { |
seq_operations contiene gli handler usati dal kernel quando lo userland legge file speciali come quelli esposti da sysfs, debugfs o procfs. Si può quindi ottenere semplicemente aprendo file come /proc/self/stat.
Poiché è una struttura composta da function pointer, ci permette sia di leakare indirizzi del kernel sia di controllare RIP. Per esempio, una semplice read sul file corrispondente porta all’esecuzione del callback start.

In `kmalloc-32` esistono anche molte altre strutture utili all'attacco.
Nell'esercizio puoi provare a cercarne altre.
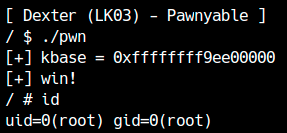
Elevazione di privilegi
In questo challenge SMAP è disabilitato, quindi possiamo fare stack pivot direttamente verso una ROP chain in userland. Costruisci la tua ROP chain e prova a ottenere l’elevazione di privilegi.
In un capitolo successivo vedremo anche tecniche per innescare race simili su sistemi single-core. ↩︎