In LK04 (Fleckvieh) affrontiamo una race condition simile a quella vista in LK01-4 (Holstein v4), ma in condizioni più severe. Per iniziare scarica i file del problema pratico LK04.
Analisi del driver
Per prima cosa leggi il sorgente del driver. Rispetto ai moduli visti fin qui è un po’ più corposo e introduce costrutti che non avevamo ancora usato. La module_open, per esempio, è fatta così:
1 | static int module_open(struct inode *inode, struct file *filp) { |
Alla quarta riga compare il macro unlikely, usatissimo nel kernel è definito in questo modo:
1 |
Serve a dare un suggerimento al compilatore su quale ramo verrà preso più spesso. È utile per controlli che quasi sempre vanno in una sola direzione, per esempio check di sicurezza o condizioni di out-of-memory.

Se il compilatore conosce il ramo più probabile, può generare codice un po' più efficiente. Qui entrano in gioco anche i meccanismi di branch prediction della CPU.
Alla riga 7 compare INIT_LIST_HEAD, il macro usato per inizializzare una list_head, cioè la lista doppiamente concatenata tipica del kernel. Ogni open riceve una lista indipendente dentro private_data.
Gli elementi collegati a quella lista hanno questo formato:
1 | typedef struct { |
Per aggiungere un elemento si usa list_add, per rimuoverlo list_del, e per iterare esistono macro come list_for_each_entry(_safe).
L’implementazione di ioctl mostra che il modulo espone quattro operazioni: CMD_ADD, CMD_DEL, CMD_GET, CMD_SET.
1 | static long module_ioctl(struct file *filp, |
CMD_ADD aggiunge un blob_list alla lista. Ogni blob può contenere fino a 0x1000 byte e riceve un ID casuale restituito in output all’utente.
CMD_DEL elimina il blob con un certo ID.
CMD_GET copia in userland i dati del blob specificato.
CMD_SET copia dal processo utente verso il blob specificato.
In sostanza è ancora un “driver che memorizza dati”, ma invece di un solo buffer ora abbiamo una lista di oggetti.
Verifica della vulnerabilità
Se hai già studiato tutto LK01, la vulnerabilità dovrebbe saltare subito all’occhio: in nessun punto viene preso un lock, quindi la race è inevitabile.
Il problema è che qui i dati sono organizzati in una lista doppiamente concatenata. Se provi a far correre in parallelo operazioni di add e delete, rischi di interferire proprio nel mezzo dell’unlink della lista, rompendo i puntatori interni e corrompendo l’heap del kernel. Risultato: crash continui e nessun modo affidabile per capire se hai ottenuto uno Use-after-Free.
Vediamolo con un esempio concreto:
1 | int fd; |
Qui due thread aggiungono e cancellano elementi in continuazione. Quando la race colpisce nel punto sbagliato, la lista si rompe e il close finale crasha mentre prova a liberarne il contenuto.
Come si fa allora a rendere sfruttabile una race in una struttura dati così delicata?
Che cos’è userfaultfd
Per race molto strette o con condizioni complesse esiste una tecnica classica: abusare di userfaultfd per fermare il kernel esattamente nel momento desiderato.
Se il kernel è compilato con CONFIG_USERFAULTFD, è disponibile la funzionalità userfaultfd, cioè la gestione di page fault in user space tramite una syscall dedicata.
Perché un utente non privilegiato possa usarla in modo completo, il flag unprivileged_userfaultfd deve essere impostato a 1. Il valore si legge in /proc/sys/vm/unprivileged_userfaultfd: di default spesso è 0, ma nella macchina di LK04 è 1.
L’utente apre un file descriptor con la syscall userfaultfd, poi lo configura con varie ioctl: handler, intervallo di memoria da monitorare, modalità di fault, e così via. Quando avviene un page fault in una delle pagine registrate, il thread handler riceve l’evento e può decidere quali dati restituire.
Il flusso è questo:
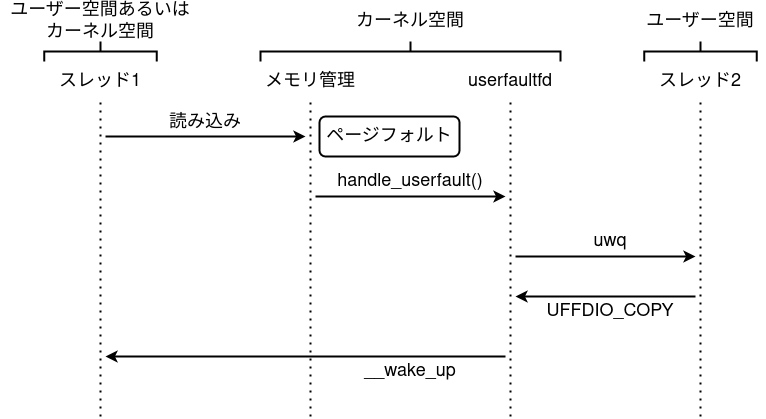
Quando il page fault si verifica, il thread che stava accedendo alla pagina resta bloccato finché l’handler non risponde. E questo vale anche se il fault nasce da una copy_to_user o copy_from_user eseguita dal kernel. In pratica possiamo congelare l’esecuzione del driver in un punto molto preciso.
Esempio di utilizzo di userfaultfd
Prova a eseguire il programma seguente:
1 |
|
register_uffd prende l’indirizzo della regione da sorvegliare e la sua lunghezza, crea il file descriptor userfaultfd e avvia il thread fault_handler_thread.
Quando avviene un page fault, il thread legge l’evento da uffd e usa UFFDIO_COPY per fornire il contenuto della pagina. Nell’esempio qui sopra il contenuto cambia a seconda di quale fault stia gestendo.
Nel main allochiamo due pagine[1], registriamo userfaultfd e poi tentiamo di leggerle. I primi due strcpy provocano un page fault al primo accesso, quindi l’handler viene invocato. Se tutto funziona, l’output mostra che le stringhe restituite dall’handler vengono effettivamente lette:
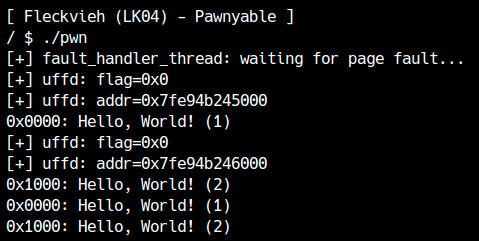

L'handler di userfaultfd gira su un thread separato, quindi può finire su una CPU diversa dal main thread. Se dentro l'handler fai nuove allocazioni, le cache per-CPU dello heap possono rendere instabile la UAF. Conviene quindi fissare l'affinità CPU con `sched_setaffinity`.
Stabilizzare la race
Adesso usiamo userfaultfd dentro l’exploit vero è proprio.
Il vantaggio è che possiamo forzare un context switch dal kernel alla nostra logica userland quando il driver sta eseguendo copy_to_user o copy_from_user. Nel driver Fleckvieh i punti interessanti sono:
copy_from_userdentroblob_addcopy_to_userdentroblob_getcopy_from_userdentroblob_set
Vogliamo ottenere uno Use-after-Free, quindi durante il blocco in uno di questi punti possiamo chiamare blob_del e liberare l’oggetto mentre il kernel sta ancora lavorando con il suo puntatore. Se congeli blob_get, ottieni un UAF read. Se congeli blob_set, ottieni un UAF write.
Il flusso è il seguente:
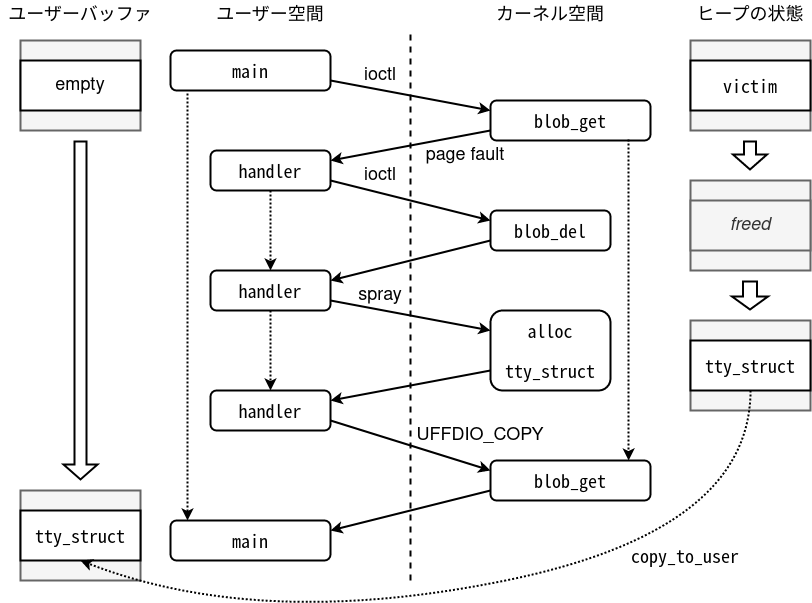
Allochiamo un buffer victim nella stessa size class di tty_struct (kmalloc-1024) e poi chiamiamo blob_get passando un indirizzo userland monitorato da userfaultfd. Quando copy_to_user prova a scrivere lì, scatta il page fault e il kernel si ferma.
Nel thread handler, mentre il kernel è bloccato, eliminiamo victim con blob_del e sprayiamo tty_struct via /dev/ptmx, in modo da riutilizzare la stessa area appena liberata. Quando lasciamo ripartire il kernel, copy_to_user continuerà a copiare partendo dall’indirizzo originario di victim, ma lì dentro ora c’è un tty_struct.
Lo stesso ragionamento vale per blob_set, che permette un UAF write.
Il PoC seguente mostra il meccanismo:
1 | cpu_set_t pwn_cpu; |
Il codice è un po’ lungo, ma il meccanismo è esattamente quello illustrato nello schema. Il vantaggio notevole è che la race diventa praticamente deterministica.
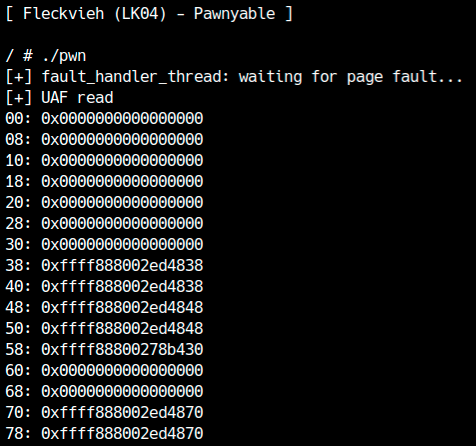
Guardando il dump leakato, noterai che l’inizio di tty_struct non viene copiato correttamente. I campi iniziali, dove ci aspetteremmo per esempio tty_operations, risultano azzerati.
Il motivo è che copy_to_user, quando lavora con una dimensione grande, inizia a leggere e copiare i primi dati prima che il page fault venga innescato. In altre parole, le primissime decine di byte appartengono ancora al buffer originario, non all’oggetto dopo la UAF.
Per fortuna il comportamento dipende dalla dimensione della copia. Se invece di usare 0x400 usi, per esempio, 0x20, il fault avviene abbastanza presto da lasciare intatti i byte che contengono il puntatore a tty_operations.

Se non sai esattamente a quale istruzione assembly avviene il page fault, il debug può diventare parecchio scomodo.
Una volta leakati KASLR e l’heap address, puoi creare anche la parte di UAF write.
Come nel capitolo precedente, l’idea è costruire un tty_struct falso con ops che punti a una function table falsa. Fai solo attenzione a un dettaglio: l’indirizzo su cui avviene la UAF write può non coincidere con quello leakato prima. Il leak proveniva dallo tty_struct liberato e riutilizzato nella prima fase, quindi ora conviene prima sprayare una falsa tty_operation nell’heap precedentemente leakato.
1 | case 2: { |
Quando hai la function table falsa nel punto giusto, puoi innescare la UAF write:
1 | // libera victim e spray di tty_struct |
Qui il contenuto da scrivere è controllato tramite copy.src, quindi basta preparare in anticipo un tty_struct finto:
1 | /* [3-1] UAF Write: sovrascrive tty_struct */ |
Se arrivi a controllare RIP, il resto dell’exploit segue lo schema ormai familiare.
Un exploit di esempio si trova qui.
Non usiamo
MAP_POPULATE, perché vogliamo che il page fault avvenga al primo accesso. ↩︎