Nel capitolo LK06 (Brahman) attaccheremo un bug del JIT/verificatore di eBPF, una delle funzionalità del kernel Linux. In questa prima parte vedremo che cos’è BPF e come si usa.
BPF
Prima di parlare di eBPF, conviene partire dal suo predecessore, BPF.
Nel tempo BPF ha ampliato molto i suoi casi d’uso e la sua architettura. A volte si distingue fra cBPF (classic BPF), cioè la versione storica, ed eBPF (extended BPF), cioè la versione moderna. In Linux attuale, però, internamente viene usato solo eBPF, quindi in questo sito parleremo semplicemente di BPF quando la distinzione non è importante.
Che cos’è BPF
BPF (Berkeley Packet Filter) è una macchina virtuale di tipo RISC integrata nel kernel Linux. Serve a eseguire nel kernel codice fornito dallo userland.
Ovviamente non si può permettere allo userland di eseguire codice arbitrario in kernel space. Per questo l’insieme di istruzioni di BPF contiene per lo più operazioni considerate sicure, come aritmetica e salti condizionati. Alcune istruzioni, però, toccano memoria o effettuano salti, quindi prima di accettare un programma BPF il kernel lo sottopone a un verificatore, che decide se il bytecode è sicuro (per esempio se non può entrare in loop infinito).
Perché prendere tutta questa precauzione pur di eseguire codice nel kernel? In origine BPF era stato progettato per il packet filtering. L’utente carica un programma BPF, e quando arriva un pacchetto il kernel esegue quel programma per decidere come filtrarlo. Oggi BPF viene usato anche in molti altri contesti: tracing, monitoraggio, seccomp e così via.
Poiché BPF viene eseguito in punti molto frequenti del sistema, interpretare il bytecode ogni volta sarebbe troppo lento. Per questo, una volta superato il verificatore, il programma BPF viene tradotto da un JIT (Just-In-Time compiler) in codice macchina nativo per la CPU.
Un JIT è un componente che genera codice nativo dinamicamente durante l’esecuzione. I browser, per esempio, usano JIT per trasformare funzioni JavaScript molto usate in codice macchina e accelerarne l’esecuzione. Anche il JIT di BPF serve esattamente a questo. Nelle versioni moderne di Linux il JIT di BPF è in genere attivo di default.
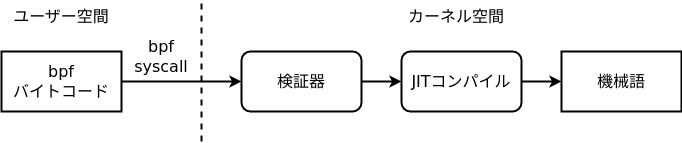
Riassumendo, il flusso di esecuzione di un programma BPF è il seguente:
- dallo userland si passa il bytecode BPF al kernel tramite la system call
bpf - il verificatore controlla che il programma sia sicuro
- se il controllo passa, il JIT lo traduce in codice macchina nativo
- quando si verifica l’evento associato, viene eseguito quel codice nativo
Quando l’evento scatta, il kernel passa al programma BPF un argomento chiamato contesto. Il programma elabora quel contesto e alla fine restituisce un valore. Per esempio, in seccomp il contesto contiene il numero della system call richiesta, l’architettura e altri metadati; il filtro BPF usa queste informazioni per decidere se la system call vada permessa, rifiutata o fatta fallire. Il kernel interpreta poi il valore di ritorno in modo coerente col tipo di programma BPF caricato.

seccomp usa ancora cBPF a livello di interfaccia, ma internamente il kernel lo converte in eBPF. Inoltre seccomp applica anche verifiche proprie, oltre al verificatore BPF generale.
Per comunicare fra userland e programma BPF si usano poi le BPF map. Una BPF map è, in pratica, una struttura key-value allocata nel kernel. Più avanti la useremo davvero scrivendo programmi BPF concreti.
Architettura di BPF
Vediamo ora più nel dettaglio la struttura di eBPF. cBPF era un’architettura a 32 bit, mentre eBPF è stato esteso a 64 bit e ha più registri.
Registri e stack
Un programma BPF ha a disposizione 512 byte di stack. I registri di eBPF sono i seguenti:
| Registro BPF | Registro x64 corrispondente |
|---|---|
| R0 | rax |
| R1 | rdi |
| R2 | rsi |
| R3 | rdx |
| R4 | rcx |
| R5 | r8 |
| R6 | rbx |
| R7 | r13 |
| R8 | r14 |
| R9 | r15 |
| R10 | rbp |
Tutti i registri, tranne R10, si possono usare come registri generici, ma alcuni hanno significati speciali.
R1contiene inizialmente il puntatore al contesto passato dal kernelR0contiene il valore di ritorno del programma BPF e va sempre inizializzato prima diBPF_EXIT_INSNR1-R5vengono usati anche come registri argomento quando il programma BPF chiama una helper function del kernelR10è il frame pointer dello stack ed è read-only
Set di istruzioni
Un programma BPF caricato da un utente normale può contenere al massimo 4096 istruzioni[1].
Poiché BPF è un’architettura di tipo RISC, tutte le istruzioni hanno dimensione fissa. Ogni istruzione occupa 64 bit ed è divisa così:
| Bit | Nome | Significato |
|---|---|---|
| 0-7 | op |
opcode |
| 8-11 | dst_reg |
registro destinazione |
| 12-15 | src_reg |
registro sorgente |
| 16-31 | off |
offset |
| 32-63 | imm |
valore immediato |
Nel campo op, i primi 4 bit identificano il codice, il bit successivo indica la sorgente e gli ultimi 3 bit rappresentano la classe. La classe distingue la famiglia di istruzioni (per esempio accessi in memoria o operazioni aritmetiche), il bit sorgente stabilisce se l’operando viene da un registro o da un immediato, e il codice specifica l’istruzione concreta all’interno di quella classe.
La documentazione completa del set di istruzioni si trova nei documenti ufficiali del kernel.
Tipi di programma
Quando si carica un programma BPF bisogna specificare per quale uso è stato scritto. Nel primo esempio del challenge useremo BPF_PROG_TYPE_SOCKET_FILTER.
cBPF aveva solo due usi principali, socket filter e syscall filter. eBPF ne supporta più di venti.
L’elenco completo è definito in uapi/linux/bpf.h.
Per esempio, BPF_PROG_TYPE_SOCKET_FILTER rappresenta il classico filtro per pacchetti. A seconda del valore di ritorno del programma, il kernel può accettare, troncate o scartare il pacchetto. Questo tipo di programma viene agganciato a una socket via setsockopt(..., SO_ATTACH_BPF, ...).
Il contesto passato al programma è una struct __sk_buff.

Il kernel non passa la sua `sk_buff` interna direttamente al programma BPF, altrimenti il layout dipenderebbe troppo dalla versione del kernel. Per BPF usa una struttura con forma stabile.
Helper function
Come accennato parlando dei registri, i programmi BPF possono chiamare alcune funzioni del kernel dette helper function. Per i socket filter, oltre agli helper di base, ne vengono esposti anche altri specifici:
1 | static const struct bpf_func_proto * |
Fra gli helper di base troviamo, per esempio, map_lookup_elem e map_update_elem, che servono a interagire con le mappe BPF. Vedremo il loro uso concreto fra poco.
Usare BPF nella pratica
Passiamo ora a usare davvero eBPF.
Se stai testando sul challenge LK06 non c’è nulla di particolare da fare. Se invece stai provando sul tuo sistema, controlla prima che gli utenti non privilegiati possano usare BPF. A partire dai fix per side-channel come Spectre, sui sistemi recenti BPF è spesso disabilitato per gli utenti normali. Lo stato si può leggere da:
1 | $ cat /proc/sys/kernel/unprivileged_bpf_disabled |
Se il valore è 0, anche un utente senza CAP_SYS_ADMIN può usare BPF. Se vale 1 o 2, bisogna abbassarlo temporaneamente a 0.
Scrivere un programma BPF
Per scrivere filtri complessi di packet filtering o tracing, normalmente si usano compilatori di livello più alto come BCC. Qui, però, ci basta usare BPF in modo leggero per scopi di exploit, quindi scriveremo il bytecode quasi a mano.
Non significa che dobbiamo scrivere byte esadecimali a mano: esistono macro C che permettono di descrivere le istruzioni in modo leggibile. Per prima cosa scarica bpf_insn.h e mettilo nella stessa directory del tuo file di test.
Proviamo un primissimo programma BPF che non fa praticamente nulla:
1 |
|
Questo programma carica un filtro BPF di tipo BPF_PROG_TYPE_SOCKET_FILTER, quindi l’ultima write sulla socket ne scatena l’esecuzione.
Il bytecode vero e proprio è qui:
1 | struct bpf_insn insns[] = { |
Assegniamo il valore immediato 4 a R0 e poi terminiamo il programma. Se tutto va bene, l’output sarà "Hell".
Il motivo è che R0 viene interpretato come valore di ritorno del filtro. Anche se abbiamo scritto 5 byte, ne riceviamo 4 soltanto: il filtro ha troncato il pacchetto.
La documentazione della socket API lo descrive così:
SO_ATTACH_FILTER (since Linux 2.2), SO_ATTACH_BPF (since Linux 3.19)
Attach a classic BPF (SO_ATTACH_FILTER) or an extended BPF (SO_ATTACH_BPF) program to the socket for use as a filter of incoming packets. A packet will be dropped if the filter program returns zero. If the filter program returns a nonzero value which is less than the packet’s data length, the packet will be truncated to the length returned. If the value returned by the filter is greater than or equal to the packet’s data length, the packet is allowed to proceed unmodified.
Usare le BPF map
Ora che abbiamo visto un filtro molto semplice, proviamo a usare le mappe BPF. Negli exploit eBPF sono quasi indispensabili, perché permettono di scambiare dati fra il programma userland e il programma BPF che gira nel kernel.
Per creare una mappa si invoca la system call bpf con comando BPF_MAP_CREATE. Nella bpf_attr bisogna specificare il tipo di mappa, in questo caso BPF_MAP_TYPE_ARRAY, e poi le dimensioni di chiave e valore. Negli exploit la chiave può essere piccola, quindi qui la fissiamo a int.
1 | int map_create(int val_size, int max_entries) { |
Per aggiornare o leggere valori in una mappa si usano rispettivamente BPF_MAP_UPDATE_ELEM e BPF_MAP_LOOKUP_ELEM:
1 | int map_update(int mapfd, int key, void *pval) { |
Con un programma come il seguente puoi verificare che i valori vengano effettivamente scritti e letti dallo userland:
1 | unsigned long val; |
Ora facciamo manipolare la mappa direttamente al programma BPF:
1 | /* prepara la mappa BPF */ |
Il programma BPF usa l’helper map_update_elem per cambiare il valore della chiave 1 nella mappa portandolo a 0x1337.
Poiché l’helper si aspetta puntatori a chiave e valore, dobbiamo prima costruire quei dati nello stack del programma BPF:
1 | BPF_ST_MEM(BPF_DW, BPF_REG_FP, -0x08, 1), // key=1 |
BPF_REG_FP corrisponde a R10, cioè al frame pointer / stack pointer del programma. In un assembly x86-64 più familiare, quelle istruzioni equivalgono grosso modo a:
1 | mov dword [rsp-0x08], 1 |
Poi prepariamo gli argomenti. In BPF gli argomenti di una helper function partono da BPF_REG_ARG1, cioè R1.
Il primo argomento di map_update_elem è il file descriptor della mappa, e lo carichiamo con:
1 | // arg1: mapfd |
Il secondo e il terzo argomento sono invece i puntatori alla chiave e al valore:
1 | // arg2: key pointer |
Il quarto argomento è un flag, che qui impostiamo a zero:
1 | // arg4: flags |
Infine chiamiamo la helper:
1 | BPF_EMIT_CALL(BPF_FUNC_map_update_elem), // map_update_elem(mapfd, &k, &v) |
Se esegui il programma, vedrai che il valore della chiave 1 nella mappa cambia prima e dopo la write che scatena il programma BPF:
1 | $ ./a.out |
Questa è la base della programmazione BPF: si combinano bytecode, helper function e mappe BPF per realizzare filtri e altra logica nel kernel.
Nel capitolo successivo parleremo del verificatore, che è la parte più importante dal punto di vista delle vulnerabilità BPF.
skb_load_bytes.)(1) Scartare il pacchetto se il payload contiene la stringa "evil".
(2) Se il payload è lungo almeno 4 byte, sostituirne i primi 4 con "evil".
Per l’utente root il limite sale fino a un milione di istruzioni. ↩︎