In questo capitolo proveremo a ottenere un’elevazione di privilegi sfruttando un bug del verifier di eBPF. Per prima cosa prepara i file del challenge LK06 (Brahman).
Analisi della patch
Per rendere il kernel vulnerabile a scopo didattico è stata applicata una patch al verifier. Il diff è in patch/verifier.diff:
1 | 7957c7957,7958 |
La modifica tocca la riga 7957 di kernel/bpf/verifier.c.[1]
Prima della patch, all’inizio di scalar32_min_max_or veniva chiamata __mark_reg32_known. Dopo la patch, quella chiamata viene commentata. Per capire perché questo è exploitable bisogna seguire bene il flusso.
Leggere scalar32_min_max_or
La funzione modificata, scalar32_min_max_or, viene chiamata da adjust_scalar_min_max_vals, cioè dalla logica che aggiorna gli intervalli dopo le operazioni ALU.
Il caso che ci interessa è BPF_OR:
1 | case BPF_OR: |
Per prima cosa viene aggiornato var_off tramite tnum_or. La semantica è semplice: se un bit è sconosciuto in uno dei due operandi e l’altro non forza quel bit a 1, allora anche il risultato lo considera incerto.
1 | struct tnum tnum_or(struct tnum a, struct tnum b) |
Per esempio:
1 | (mask=0xffff0000; value=0x1001) |
produce:
1 | (mask=0xffffef00; value=0x1003) |
Dopo l’aggiornamento di var_off, entra in gioco scalar32_min_max_or. Il punto eliminato dalla patch viene eseguito quando src_known e dst_known sono entrambi veri:
1 |
|
tnum_subreg_is_const ritorna true quando i 32 bit bassi sono costanti. Quindi in quel punto il verifier sa che entrambe le subregister a 32 bit sono costanti.
Normalmente avrebbe dovuto chiamare __mark_reg32_known:
1 | static void __mark_reg32_known(struct bpf_reg_state *reg, u64 imm) |
Questa funzione riallinea i bounds a 32 bit con il valore costante appena ottenuto.
Il commento della patch dice però: “scalar_min_max_or will handler the case”. Andiamo quindi a vedere anche scalar_min_max_or:
1 | static void scalar_min_max_or(struct bpf_reg_state *dst_reg, |
Questa è la controparte a 64 bit. Se entrambi i registri interi a 64 bit sono costanti, chiama __mark_reg_known, che aggiorna sia i bounds a 64 bit sia quelli a 32 bit:
1 | /* This helper doesn't clear reg->id */ |
Quindi, se l’intero registro a 64 bit è costante, il commento della patch sembra ragionevole: non serve davvero __mark_reg32_known.
Il problema è il caso intermedio: i 32 bit bassi sono costanti, ma i 32 bit alti no.
In quel caso scalar32_min_max_or ritorna subito, mentre scalar_min_max_or non entra nel ramo che chiama __mark_reg_known.
Finisce invece nel percorso seguente:
1 | /* We get our maximum from the var_off, and our minimum is the |
La patch quindi lascia in giro un registro con informazioni parzialmente aggiornate. Bisogna capire se questo sia sufficiente a creare un’incoerenza utile.
Leggere __update_reg32_bounds
La funzione interessante è __update_reg32_bounds:
1 | static void __update_reg32_bounds(struct bpf_reg_state *reg) |
Qui sta il bug.
Dato che __mark_reg32_known non è stato chiamato, i bounds a 32 bit (u32_min_value, u32_max_value, ecc.) possono contenere ancora lo stato precedente.
Per semplificare, ragioniamo sui valori unsigned:
1 | reg->u32_min_value = max_t(u32, reg->u32_min_value, (u32)var32_off.value); |
Se i 32 bit bassi sono costanti, allora var32_off.mask == 0, quindi diventa:
1 | reg->u32_min_value = max(reg->u32_min_value, var32_off.value); |
Supponi che il vecchio registro avesse come minimo e massimo lo stesso valore X, e che dopo l’OR il risultato reale dei 32 bit bassi diventi X|Y.
Se X|Y > X, allora:
1 | reg->u32_min_value = max(X, X|Y); // min = X|Y |
Otteniamo così una situazione impossibile: u32_min_value > u32_max_value.
Riproduzione del bug
Prendiamo il caso più semplice possibile: X = 0, Y = 1.
Costruiamo due registri:
1 | R1: var_off=(value=0; mask=0xffffffff00000000) |
Facendo BPF_OR(R1, R2), succede questo:
var_offdiventa(value=0xfffffffe00000001; mask=0x100000000)u32_min_value = max(0, 1) = 1u32_max_value = min(0, 1) = 0
Quindi il verifier produce un registro “rotto”, in cui il minimo a 32 bit è 1 ma il massimo è 0.
Possiamo verificarlo con il seguente programma:
1 | // Crea una BPF map |
Se carichi il programma e stampi il verifier_log, vedrai qualcosa di questo tipo:
1 | / $ ./pwn |
Alla riga 14 si vede esplicitamente:
1 | R1_w=Pscalar(...,s32_min=1,s32_max=0,u32_min=1,u32_max=0) |
quindi il tracking si e rotto.

Questa famiglia di bug non è inventata: in passato problemi simili su OR, AND e XOR hanno davvero portato a vulnerabilità come CVE-2021-3490.
Leak di indirizzi
Quando riusciamo a creare un registro con min_value > max_value, ci sono vari modi per sfruttarlo. Il primo uso comodo e ottenere un leak di indirizzi.
In eBPF e permesso sommare o sottrarre valori scalari a un puntatore. L’aggiornamento dei bounds nel caso di ptr +/- scalar e implementato in adjust_ptr_min_max_vals:
1 | static int adjust_ptr_min_max_vals(struct bpf_verifier_env *env, |
Se il registro scalare ha bounds incoerenti, il risultato dell’operazione viene degradato a scalar unknown tramite __mark_reg_unknown.
Questo è molto utile: se sommi il registro corrotto a un puntatore di map, il risultato non viene più trattato come puntatore a map, ma come semplice valore scalare. Un valore scalare può essere scritto dentro una BPF map, quindi puoi trasformare il puntatore in un leak.
Per farlo, però, non bastano i bounds corrotti a 32 bit: serve estenderli al registro a 64 bit. Si può fare con BPF_MOV32_REG.
1 | ... |
Se il programma va a buon fine, il valore scritto nella map corrisponde all’indirizzo del suo stesso elemento. Tieni solo conto che R1 conteneva in realtà 1, quindi il puntatore leakato risulta traslato di un byte.
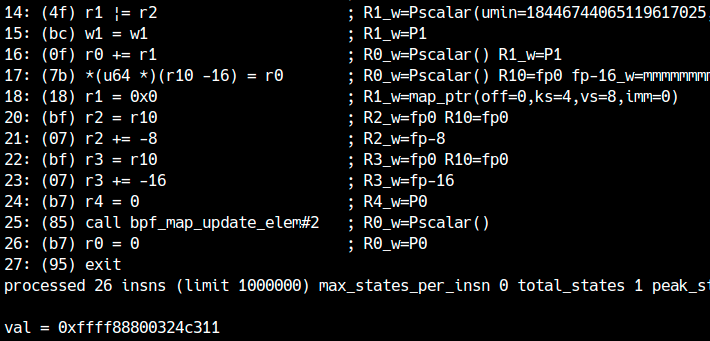
Con gdb puoi verificare che l’indirizzo corrisponde davvero all’area dati della map:
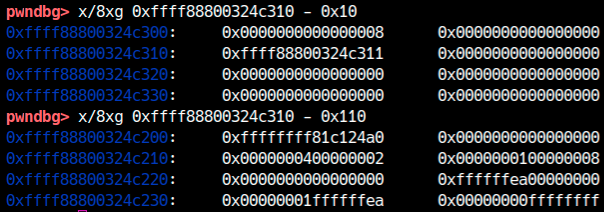
Se sottrai 0x110, arrivi all’inizio della struttura bpf_array, che include il campo ops di bpf_map. In altri exploit questo puntatore può diventare un ottimo bersaglio per la corruzione.
Anche senza usare questo meccanismo specifico, l’indirizzo di una map torna molto utile, quindi conviene incapsulare il leak in una funzione dedicata.

Quando fai debug come root, ricorda che il kernel permette leak di puntatori che in un contesto non privilegiato verrebbero bloccati. La verifica finale va sempre fatta da utente normale.
Out-of-bounds access
Nel capitolo sul verifier abbiamo visto che, dal 2022, ALU sanitation complica molto gli out-of-bounds “classici”. Cominciamo comunque da un caso semplice, per capire bene la tecnica.
Esiste una scorciatoia: se la funzione bpf_bypass_spec_v1 ritorna true, il verifier salta ALU sanitation. Questo succede per default quando il programma viene caricato come root.
Quindi i primi esperimenti di OOB conviene farli come root.
Costruire una costante con tracking corrotto
Negli exploit contro il verifier è spesso molto utile costruire una costante che il verifier creda essere X ma che in realtà valga Y, con X != Y.
Il caso migliore è quando il verifier pensa 0 ma il valore reale è diverso da zero: in quel modo, ogni moltiplicazione o somma con un puntatore resta “innocua” per il verifier ma sposta davvero l’accesso in memoria.
Partiamo dal registro corrotto R1, che ha u32_min_value = 1 e u32_max_value = 0, ma valore reale pari a 1.
Ora costruiamo un secondo registro R2 sano, con bounds [0, 1] e valore reale pari a 1.
Se sommiamo R1 + R2, il verifier ottiene:
1 | [1,0] + [0,1] = [1,1] |
cioè considera il risultato una costante esatta pari a 1.
Ma i valori reali che si stanno sommando sono 1 e 1, quindi il risultato reale è 2.
Se poi sottraiamo 1, otteniamo esattamente quello che ci serve: un registro che il verifier considera 0, ma che in realtà vale 1.
Per costruire R2 con intervallo [0,1] basta usare una map o una condizione che scarti i casi oltre 1:
1 | // Crea una BPF map |
Se controlli il contenuto della map dopo l’esecuzione, vedrai che il valore reale scritto è 1, anche se il verifier crede che R1 valga 0.
Verifica dell’out-of-bounds
Ora che abbiamo un registro che il verifier crede uguale a 0 ma che in realtà vale 1, possiamo moltiplicarlo per una costante e usarlo come offset per uscire dai limiti di una map.
Il programma seguente costruisce un offset che il verifier pensa 0 ma che in realtà vale 0x100, lo somma al puntatore alla map è poi fa una BPF_LDX_MEM fuori limite:
1 | int main() { |
Se lo esegui come root, leggerai un valore che non appartiene affatto alla map:
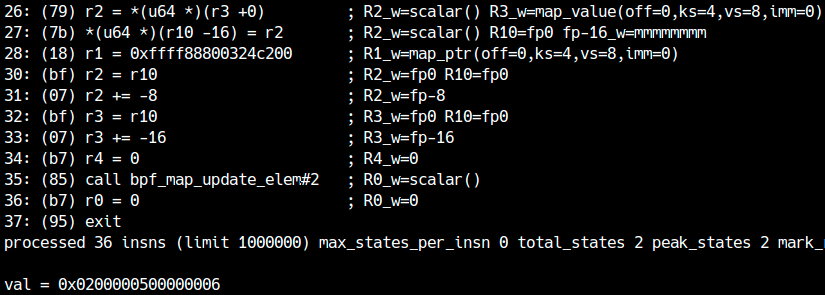
Con gdb si verifica facilmente che il valore leakato si trova davvero 0x100 byte oltre l’area dati della map:

Se provi invece a passare direttamente 0x100 come costante, il verifier blocca tutto. Quindi l’accesso fuori limite è davvero un effetto del bug.
Da utente normale, però, la stessa tecnica fallisce. ALU sanitation riscrive la somma con il puntatore in modo da neutralizzare l’offset fuori range, è il programma finisce semplicemente per leggere il valore legittimo già presente nella map:
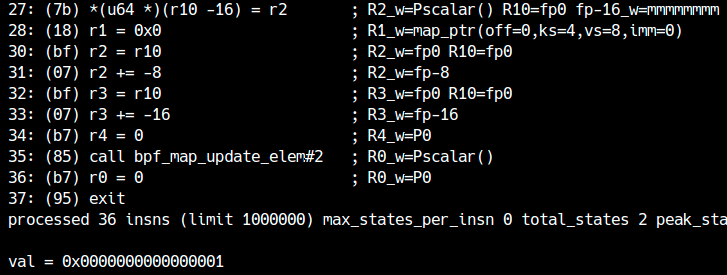

Prima dell'introduzione di ALU sanitation, exploit di questo tipo contro i campi di `bpf_map` erano molto più diretti.
Bypass di ALU sanitation
Per fortuna il kernel target, 5.18.14, lascia aperta un’altra strada.
L’idea è questa: se il verifier patcha i ptr +/- scalar, allora conviene far eseguire l’accesso fuori limite a una helper function che usa offset e size passati come argomenti.
Fra gli helper disponibili ai programmi socket filter, uno particolarmente utile è skb_load_bytes:
1 | BPF_CALL_4(bpf_skb_load_bytes, const struct sk_buff *, skb, u32, offset, |
Questa helper copia nel programma BPF i byte del pacchetto ricevuto sul socket. Gli argomenti sono:
arg1: contesto (skb)arg2: offset da cui leggere nel pacchettoarg3: buffer di destinazionearg4: lunghezza da copiare
Il punto importante è che il controllo dei limiti avviene dentro l’helper e non è neutralizzato da ALU sanitation nello stesso modo del classico ptr + scalar.
Possiamo allora preparare un registro che il verifier creda uguale a 1, ma che in realtà valga 0x10, e usarlo come lunghezza di skb_load_bytes. Se la map ha size 8, copiare 16 byte significa ottenere una write fuori limite.
1 | ... |
Dal socket inviamo 16 byte controllati:
1 | char payload[0x10]; |
Il risultato è una write fuori limite sulla heap del kernel:

A questo punto potresti già tentare un exploit corrompendo il ops di una seconda map o qualche altro oggetto heap adiacente. Ma c’è una strada ancora più pulita.
Creazione di AAR/AAW
Ricorda che lo stack BPF può contenere puntatori e che il verifier continua a trattarli come tali.
Se usi skb_load_bytes per fare una scrittura fuori limite sullo stack BPF, puoi sovrascrivere un puntatore valido già presente nello stack con un indirizzo arbitrario scelto dall’utente.
Il verifier però continua a considerare quel valore come un puntatore trusted. Di conseguenza, se in seguito lo ricarichi con BPF_LDX_MEM, puoi dereferenziarlo o scriverci sopra: hai ottenuto AAR/AAW.
Lo schema e:
Dentro il PoC seguente, il puntatore valido viene salvato in FP-0x18, poi skb_load_bytes lo sovrascrive con l’indirizzo arbitrario inviato nel payload.
Alla fine il programma rilegge FP-0x18 come puntatore e lo usa per leggere o scrivere in memoria arbitraria.
PoC di AAR/AAW
1 | /** |
Bypass di kASLR ed elevazione dei privilegi
A questo punto hai già tutto il necessario.
Dal leak dell’indirizzo della map puoi raggiungere strutture come bpf_map->ops e ricavare così il base address del kernel. Una volta calcolato kbase, con AAW puoi riscrivere variabili globali come modprobe_path, oppure puntatori interessanti interni al sottosistema BPF.
Completa da solo l’exploit finale. Un’implementazione di riferimento è disponibile qui.
min_value > max_value per leakare l'indirizzo di una BPF map sfruttando adjust_ptr_min_max_vals.(1) Completa l'exploit senza leakare prima l'indirizzo di BPF map, stack BPF o contesto.
(2) Poi completa anche una variante che usi solo l'heap overflow ottenuto con
skb_load_bytes, senza passare dallo stack BPF.
La versione del kernel usata qui è Linux 5.18.14. ↩︎